RDM Repositories
Data repositories play a crucial role in research data management. The RDM division provides researchers with access to various data repositories, including Open Data USM, Repository@USM, Mendeley Data, Figshare, and Zenodo. These data repositories allow researchers to store and share their research data securely and make it available to other researchers for future use. Open Data USM and Repository@USM are institutional repositories designed to store and share research data produced by USM researchers. Mendeley Data, Figshare, and Zenodo are third-party data repositories that offer additional features such as data visualization tools, the ability to publish datasets with a DOI, and integration with other research tools. These data repositories are crucial in ensuring that research data is managed effectively and can be reused by other researchers, leading to more impactful research outcomes.
-

Figshare is a free, online digital repository where researchers can preserve and share their research outputs, including figures, datasets, images, and videos. Users can upload files in any format, and items are attributed a Digital Object Identifier. All files are released under a Creative Commons license, CC-BY for most files and CC0 (public domain) for datasets. Figshare also tracks the download statistics for hosted materials, acting in turn as a source for alternative scholarly impact metrics (alt metrics). By encouraging publishing of figures, charts, and data, rather than being limited to the traditional entire ‘paper’, knowledge can be shared more quickly and effectively. This webinar will introduce the platform, how to best use it, and showcase examples of successful data sharing and its impact.
Zenodo is a general-purpose data repository built on open source software that accepts all forms of research output from data files to presentation files. It was developed by the European Organization for Nuclear Research (CERN), but is open to researchers from outside the EU. Data is stored in the CERN Data Center, which provides long-term preservation.
Data size and format: - File size limit: 2GB, but Zenodo will work with researchers to upload larger files. The infrastructure has been tested with files up to 10GB in size.
- Dataset size limit: No limit, although quotas for uploads may be introduced in the future.
- Data types and formats hosted: All file types are accepted. Files are categorized as: publications, posters, presentations, datasets, images, software, videos/audio, and lessons. Zenodo also integrates with GitHub to deposit GitHub repositories for sharing and long-term preservation.
Data licensing: Users can choose from a long list of licenses, with the default being Creative Commons Zero (CC0). Data attribution and citation tools: Zenodo assigns DOIs to each file upload, or allows the user to enter a previously assigned DOI. User access controls: Users can choose to deposit files under open, embargoed, restricted, or closed access. For embargoed files, the user can choose the length of the embargo period, and the content will become publicly available automatically at the end of the embargo period. Users may also deposit restricted files and grant access to specific individuals. Data access tools: - Search: Free-text search functionality is provided. Machine-readable metadata are also recorded, according to the Invenio Digital Library Framework. Zenodo communicates with existing services, such as Mendeley, ORCID, CrossRef, and OpenAIRE for pre-filling metadata. All metadata is openly available on the site, regardless of the type of data access selected.
Download: In addition to individual file downloading, Zenodo has an OAI-PMH API for programmatic data and metadata access, as described in the API documentation. - Proprietary file format access: none
- Data analysis: none
Cost: Free Researchers and students are encouraged to upload their research output in the USM Communities here https://zenodo.org/communities/usm/ to facilitate sharing and discovery of information. All types of research outputs can be included in this Community (Publication, Poster, Presentation, Dataset, Image, Video/Audio, Software, Lesson, Other).
Who Zenodo is well suited for:- any researcher who wants to share data with collaborators or the public
- any researcher seeking a DOI for a dataset or group of related datasets
Where Zenodo falls short:
- The 2GB individual file size limit may be problematic.
- Proprietary file types are accessible only to users with access to the necessary software.
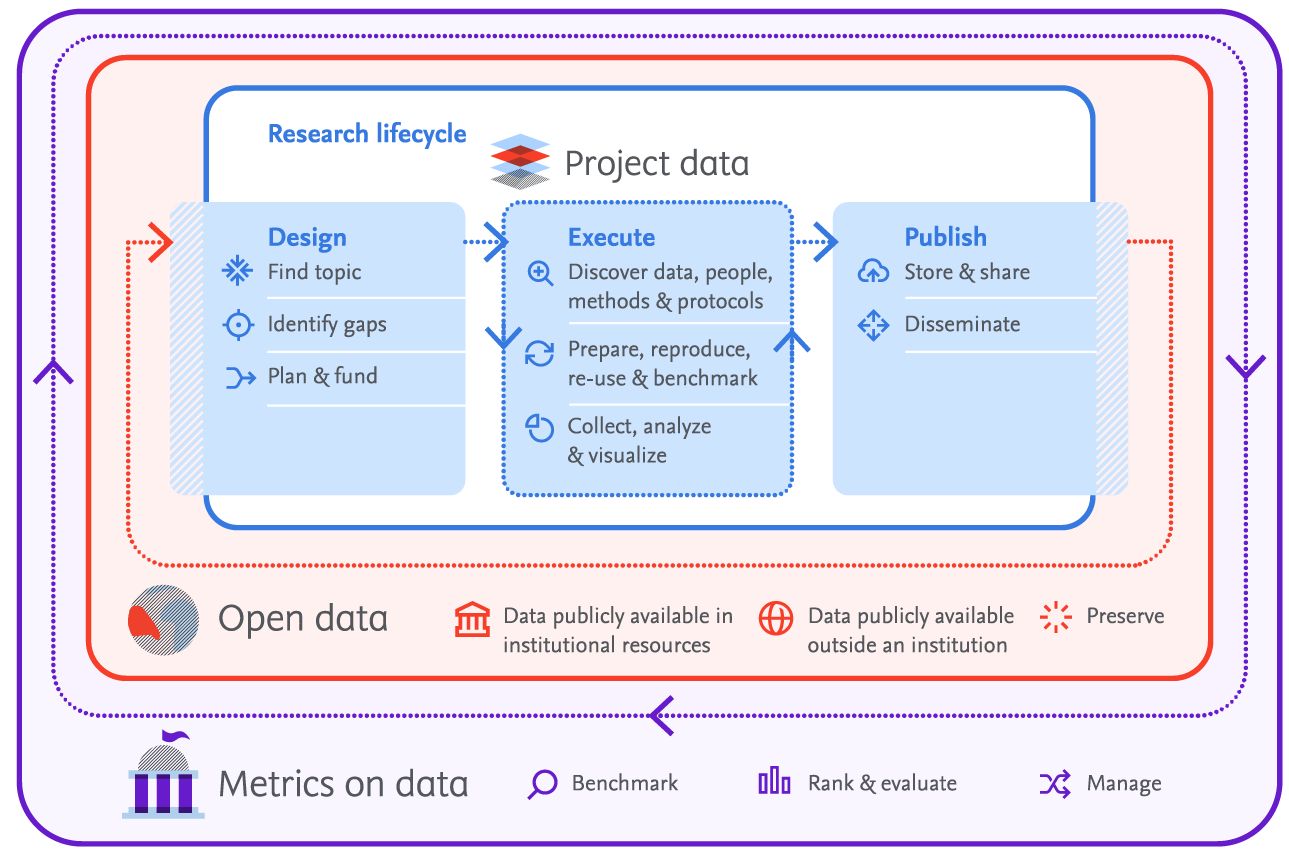
4 principles for unlocking the full potential of research data (Mendeley Data)
1. Data needs to be discoverable.
As with all research outputs, data that’s accessible is limited in value. To truly unlock the potential of research data, it needs to be discoverable. That can mean the data is easily found in search results or when stored in institutional repositories or publisher platforms, or that it’s presented by recommendation engines according to parameters set by researchers. The starting point here is that we expect that researchers and the data community have good intentions to add high-quality metadata to the research data. However, this process has a limit: we believe data platforms should automatically and dynamically enrich the metadata using AI techniques to improve discoverability over a longer period of time. This is called deep-data indexing. Related to that is the idea of comprehensibility.
2. Data needs to be comprehensible.
For data to be reused, it needs to be clear which units of measurements were used, how the data was collected, and which abbreviations and parameters are used. Data provenance is crucial for comprehension. One of the reasons we saw the Mendeley Data notebook tool Hivebench as an essential component in our research data management platform was that it helps researchers keep very structure datasets, which they can then be shared in a way that’s standardized and comprehensible. Any lab notebook tool (ELN tool) will help to annotate the data; it is important that these tools do not stand by themselves but are integrated into the broader data ecosystem. 3. Researchers should be able to take ownership of their data.
3. Researchers should be able to take ownership of their data.
We understand how important it is for institutions to protect their data, and as such, private data needs to stay private with users and institutions controlling who gets to access data and when. While access to data is important, it’s not something that can be forced; any data management system needs to ensure that the researchers set the parameters for sharing. For this reason, it’s important for institutions to be able control where the data is stored without researchers having to change their way of working.
Connected to the principle of ownership is the idea that data should be citable. One of the barriers to data sharing has been that it requires extra work from researchers for little reward. Data citations have the potential to change that because they can be easily incorporated in the current reward system based on article citation.
4. Research data management (RDM) solutions need to be interoperable.
In addition to helping researchers collect their data in a more structured way and ensuring that they retain control of how data is shared, RDM tools need to connect seamlessly to external collaborative resources. In the case of Mendeley Data, we wanted to create a flexible RDM platform; modules are designed to be used together, as standalone pieces, or combined with other RDM tools that you or your researchers may already use. Integration with the global RDM ecosystem and other Elsevier research intelligence solutions is possible through open APIs.
SOURCE: https://www.elsevier.com/connect/4-principles-for-unlocking-the-full-potential-of-research-data
Mendeley Data helps your researchers to:- Discover relevant research data
- Comply with funders’ mandates
- Prevent re-work
- Save time searching, collecting and sharing data
- Improve the impact of research and increase data reuse
 SOURCE: https://blog.mendeley.com/2019/05/15/effective-research-data-management-with-mendeley-data/
SOURCE: https://blog.mendeley.com/2019/05/15/effective-research-data-management-with-mendeley-data/






Disclaimer
USM Library will not be responsible for any loss or damage caused by the use of any information obtained from this website.
Contact Us
Hamzah Sendut Library, Universiti Sains Malaysia, 11800, Penang, Malaysia
Tel : +604 - 653 3720
Fax : +604 - 654 2508
Email: ![]()